String sub = new String( oldString.substring(0, 4) );
Wednesday, July 29, 2009
String.substring is dangerous
String.substring() will create a new string and old one can not be garbage collected. Please use below.
Tuesday, July 28, 2009
Good Developer
A good Developer should be able to learn, adapt, and apply but not be
limited to past experience.
limited to past experience.
Monday, July 27, 2009
What is the difference between class adapter and object adapter design pattern
Object adapter contains adaptee , and class adapter inherits from adaptee.
If you have multiple adaptees, then you have to use object adapter.
If you have multiple adaptees, then you have to use object adapter.
// Object adapter version
public class ReportGenerator implements OldReporter {
private NewReportWriter newReporter = new NewReportWriter()
public void writeHeader(String headerData) {
newReporter.generateHeaderLines(headerData)
}
}
// Class adapter version
public class ReportGenerator extends NewReportWriter
implements OldReporter {
public void writeHeader(String headerData) {
generateHeaderLines(headerData)
}
}
Friday, July 24, 2009
design pattern Singleton
- public class SimpleSingleton {
- private SimpleSingleton singleInstance = null;
- //Marking default constructor private
- //to avoid direct instantiation.
- private SimpleSingleton() {
- }
- //Get instance for class SimpleSingleton
- public static SimpleSingleton getInstance() {
- if(null == singleInstance) {
- singleInstance = new SimpleSingleton();
- }
- return singleInstance;
- }
- }
public static synchronized SimpleSingleton getInstance() { }
Thursday, July 23, 2009
How to do as architect
1. Management of non-functional requirement
a. help the stakeholders to list all non-functional requirement:
performance, security, scalability, availability, maintainability, audit, extensibility and I18N
2. Architecture definition
Every system has a architecture, but not every has a architecture defined. The architecture definition process lets you think about how you're going to take the requirements plus any constraints imposed upon you and figure out how you're going to solve the problem. Architecture definition is about introducing structure, guidelines, principles and leadership to the technical aspects of a software project.
3. Technology selection
4. Architecture evaluation
Risk, benefit.
5. Architecture collaboration
Go through it and make sure everybody involved understand it and buy in.
6. Ownership of big picture.
7. leadership
Taking responsibility, providing technical guidance, making technical decisions and having the authority to make those decisions
8. Coaching and mentoring
Sharing experience with other members.
9. Design, development and testing
10. Quality assurance
a. help the stakeholders to list all non-functional requirement:
performance, security, scalability, availability, maintainability, audit, extensibility and I18N
2. Architecture definition
Every system has a architecture, but not every has a architecture defined. The architecture definition process lets you think about how you're going to take the requirements plus any constraints imposed upon you and figure out how you're going to solve the problem. Architecture definition is about introducing structure, guidelines, principles and leadership to the technical aspects of a software project.
3. Technology selection
4. Architecture evaluation
Risk, benefit.
5. Architecture collaboration
Go through it and make sure everybody involved understand it and buy in.
6. Ownership of big picture.
7. leadership
Taking responsibility, providing technical guidance, making technical decisions and having the authority to make those decisions
8. Coaching and mentoring
Sharing experience with other members.
9. Design, development and testing
10. Quality assurance
Tuesday, July 21, 2009
String, Stringbuilder, and stringbuffer
String is good for substring, not add extra time.
For concat(), string builder is better, but JVM automatically does it for you.
Stringbuilder is not thread-safe
Stringbuffer is thread-safe.
For concat(), string builder is better, but JVM automatically does it for you.
Stringbuilder is not thread-safe
Stringbuffer is thread-safe.
TDD steps
1. Write the test
2. Write the comments inside the test to describe the function
3. Write sub-test for each function inside the test.
4. Run the test, make the testing running automatically.
5. Write the code.
6. re-factory the test.
2. Write the comments inside the test to describe the function
3. Write sub-test for each function inside the test.
4. Run the test, make the testing running automatically.
5. Write the code.
6. re-factory the test.
Monday, July 20, 2009
reading comments: Lazy Load
Lazy Load is one of the object relational behavioral patterns. With lazy load, an object does not contain all of the data you need but knows how to get it when it is needed. This pattern is commonly found in most of the OR mappers, e.g. Hibernate.
lazy initialization
With lazy initialization, every access to the field is checked against a special value, e.g. null value. If the value is not found, then the object needs to perform some logic, e.g. lookup from database, before returning.
virtual proxy
A virtual proxy is an object that looks like the object that should be in the field, but actually doesn’t contain anything. Only when one of it’s methods is called does it load the correct object from the database.
value holder
A value holder is used as a generic Lazy Load. It is an object that wraps some other object. To get the underlying object you ask the value holder for the value, and the first access will pull the data from the database.
lazy initialization
With lazy initialization, every access to the field is checked against a special value, e.g. null value. If the value is not found, then the object needs to perform some logic, e.g. lookup from database, before returning.
virtual proxy
A virtual proxy is an object that looks like the object that should be in the field, but actually doesn’t contain anything. Only when one of it’s methods is called does it load the correct object from the database.
value holder
A value holder is used as a generic Lazy Load. It is an object that wraps some other object. To get the underlying object you ask the value holder for the value, and the first access will pull the data from the database.
XmlBeanFactory vs ClassPathXmlApplicationContext
In my previous blog, I explained how to use ClassPathXmlApplicationContext. Today when I debug a application, I found below issues regarding XmlBeanFactory.
When we use XmlBeanFactory, TX annotation is not working. and it does not even load when you say in XML file.
So if you want to use annotation, please use ClassPathXmlApplicationContext. I believe in WEB application, tomcat system actually uses ClassPathXmlApplicationContext. So in order to make your code testing separately, please do not use XmlBeanFactory.
Below it is the example of XmlBeanFactory and ClassPathXmlApplicationContext
XmlBeanFactory factory = new XmlBeanFactory(new ClassPathResource(
"applicationContext2.xml"));
InvoiceProcessDao process = (InvoiceProcessDao)factory.getBean("invoiceProcess");
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext3.xml");
InvoiceProcessDao process = (InvoiceProcessDao)ctx.getBean("invoiceProcess");
process.checkPayment();
System.out.println(" Over") ;
When we use XmlBeanFactory, TX annotation is not working. and it does not even load when you say
So if you want to use annotation, please use ClassPathXmlApplicationContext. I believe in WEB application, tomcat system actually uses ClassPathXmlApplicationContext. So in order to make your code testing separately, please do not use XmlBeanFactory.
Below it is the example of XmlBeanFactory and ClassPathXmlApplicationContext
XmlBeanFactory factory = new XmlBeanFactory(new ClassPathResource(
"applicationContext2.xml"));
InvoiceProcessDao process = (InvoiceProcessDao)factory.getBean("invoiceProcess");
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext3.xml");
InvoiceProcessDao process = (InvoiceProcessDao)ctx.getBean("invoiceProcess");
process.checkPayment();
System.out.println(" Over") ;
Monday, July 13, 2009
Junit best pratise
JUnits - Do’s and Dont’s
Posted by: Mahesh Tabib on July 10, 2009 DIGG
After the Junit cleanup last whole month, here are my few cents.A JUnit test case can contain multiple tests. Each test is implemented by a method. The declaration of a test method must comply to a set of conventions in order to help JUnit and associated tools to automate the discovery and execution of tests. These conventions are:
1. The name of the method must begin with “test”, like in “testValidateOperator”,
2. The return type of a test method must be null,
3. A test method must not throw any exception,
4. A test method must not have any parameter.
There are a few details of which you should be aware of when writing JUnit tests. First of all, when executing a test case, JUnit will instantiate the test case class as many time as there are test methods. That is, each test method will be executed on a different instance of the test case class. Before calling the test method, JUnit will call the setUp() method. The tearDown() method will be called after the test method completes – successfully or not. The setUp() and tearDown() methods should be used to create and then clean up the test environment.
Good practices to be followed while writing a JUnit:
• Write tests for methods that have the fewest dependencies first. If you start by testing a high-level method, your test may fail because a subordinate method may return an incorrect value to the method under test. This increases the time spent finding the source of the problem, and you will still have to test the subordinate method anyway to be sure it does not contain other bugs.
• Tests should be logically simple as possible, preferably with no decisions at all. Every decision added to a test method increases the number of possible ways that a test method can be executed. Testing is meant to be a controlled environment; the only thing you want to change is the input to the method under test, not the test method itself.
• Wherever possible, use constant as expected values in your assertions instead of computed values. Consider these two assertions:
returnVal = getDiscountCode(input);
assertEquals(returnVal, computeDiscountCode(input));
assertEquals(returnVal, “023”);
In order for computeDiscountCode() to return the proper result it probably has to implement the same logic as the getDiscountCode(), which is what you are trying to test for in the first place. Further, suppose you fixed a defect in the getDiscountCode (). Now you have to change computeDiscountCode () in the same manner. The second assertion is easier to understand and maintain.
• Each unit test should be independent of all other tests.
A unit test should execute one specific behavior for a single method. Validating behavior of multiple methods is problematic as such coupling can increase refactoring time and effort. Consider the following example:
void testAdd()
{
int return1 = myClass.add(1,2);
int return2 = myclass.add(-1,-2);
assertTrue (return1 – return2 == 0);
}
If the assertions fails in this case, it will be difficult to determine which invocation of add() caused the problem.
• Each unit test should be clearly named and documented.
The name of the test method should clearly indicate which method is being tested because improperly named tests increase maintenance and refactoring efforts. Comments should also be used to describe the test or any special conditions.
• All methods, regardless of visibility, should have appropriate unit tests.
Public, private and protected methods that contain data and decisions should be unit tested in isolation.
• One assertion per test case.
Avoid using multiple assertions in one test case. For example, if a test case with five assertions fails on the first assertion, then the remaining four are not executed. Only when the first assertion is corrected will the other assertions execute. If assertion two fails, then that also must be corrected before the remaining three assertions are verified. Although the unit test file may be large, it will be easier to find and fix defects.
• Create unit tests that target exceptions.
Exceptions are thrown when a method finds itself in a state it cannot handle. These cases should be tested just like a method’s normal state of operations. If a method is declared to throw one or more exceptions, then unit tests must be create that simulate the circumstances under which those exceptions could be thrown. The unit tests should assert that the exceptions are thrown as expected.
Please let me know if this helps. Happy coding Junits…!!
Wednesday, July 8, 2009
SOA Security post
http://domagojtechtips.blogspot.com/2007/08/cxf-spring-and-ws-security-putting-it.html
http://cwiki.apache.org/CXF20DOC/ws-security.html
http://cwiki.apache.org/CXF20DOC/ws-security.html
Tuesday, July 7, 2009
Notes for Data Warehousing
1. Type of Data
a. Operational Data ( OLTP)
What is the salary of John?
What is the phone number of the person who is in charge of Depta
How many people are rated as excellent?
b. Historical Data (OLAP)
How is the trend in the past 2 years?
How is summary of something?
2. What is Data Warehousing?
4. Data Marts:
a. Dirt Data
Schema: Forming an integrated schema structure from different data source, cleaning data and managing from different DS.
a. Operational Data ( OLTP)
- Data that works
- Frequent updated and queried
- Normalized for efficient search and update
- Fragmented and local relevance.
- Point query, query access individual tables.
What is the salary of John?
What is the phone number of the person who is in charge of Depta
How many people are rated as excellent?
b. Historical Data (OLAP)
- Data that tells
- Very infrequent update
- Integrated data set with global relevance.
- Analytical queries that require huge amounts of aggregation.
- performance issue, need quick response time.
How is the trend in the past 2 years?
How is summary of something?
2. What is Data Warehousing?
- An infrastructure of manage historical data
- Designed to support OLAP queries involving gratuitous use of aggregation
- Post retrival processing(reporting)
4. Data Marts:
- Segments of OLTP
- Data Warehouse is a collection of data marts
a. Dirt Data
- Lack of standardization
- Missing or duplicate data
- Inconsistent.
- Can not be fully automated
- GIGO
- Require data considerable knowledge
- Complex
- Data analysis
- Definition of transformation rule
- Rules verification
- Transformation
- Backflow: re-populate data
Schema: Forming an integrated schema structure from different data source, cleaning data and managing from different DS.
Reading: Tomcat security for clear password
How to Secure Tomcat Database Passwords for Java
In production environments there are features of Tomcat that don't pass security audit reviews
| October 3, 2007 11:45 AM EDT | Reads: | 30,463 |
Tomcat is a great reference implementation of the Java EE specification and is intended for desktop use by developers who are starting to learn about Java EE or those who work on enterprise applications and need an EE server for development. However because Tomcat is free it finds its way into production environments. In this environment there are features of Tomcat that don't pass security audit reviews. One of these features is the use of clear text passwords in the server.xml file to create data sources. The purpose of this article is to show how encryption of the username and password can be implemented thus closing a potential security vulnerability.
 Configuring a container managed data source with Tomcat is easy and well documented under the "JDBC DataSources" section of Tomcat's documentation (this article uses Tomcat 5.0.28). The data source configuration information is stored in TOMCAT/conf/server.xml. The resource is defined using the
Configuring a container managed data source with Tomcat is easy and well documented under the "JDBC DataSources" section of Tomcat's documentation (this article uses Tomcat 5.0.28). The data source configuration information is stored in TOMCAT/conf/server.xml. The resource is defined using the
auth="Container"
type="javax.sql.DataSource"
/>
The name attribute defines where the resource is bound in JNDI. The auth attribute will have either the value Application or Container. Container means Tomcat will provide the username and password to connect to the resource whereas Application means the application will provide them. Container is specified because the username and password will be entered in server.xml. The type attribute is the fully qualified name of the class returned when the resource is looked up using JNDI.
Next the resource needs to be configured. This is the purpose of the
The name attribute has the value jdbc/TestDB, which must match a
Finally, the application has to be configured to use this data source. This is done by referencing the data source in /META-INF/context.xml of the application's WAR. A
name="jdbc/SpiderMan"
type="javax.sql.DataSource"
/>
The type attribute is the fully qualified name of the class returned when the resource is looked up using JNDI. The global attribute must match a
CIO, CResources
For development environments or personal use this configuration is acceptable, however, in a production environment the clear text username and password in
While Yahooing! I was surprised to discover I couldn't find any instructions addressing this issue. Most search results related to debating if securing the clear text username and password is even necessary. The general consensus seemed to be this security is not necessary for two reasons. One, if an intruder compromises a production server in a way that would allow read access to server.xml then the clear text username and password is the least security concern. Two, Tomcat is a reference implementation so it shouldn't be used in a production environment. Although these are lively debates and can spark great topics of conversation they do not address the issue. What I need is a way to get rid of the clear text username and password.
I will present three possible solutions to this issue. The first two are custom solutions involving application updates while the third takes advantage of Tomcat's built-in extensibility, requires no application updates and so is a much more attractive solution.
The first solution is to bypass Tomcat altogether and not configure a data source. With no data source there's no clear text username and password in server.xml so the problem is solved. However applications still need database connections. With no container-managed database pool each application will have to do its own pooling. This brings up all sorts of problems. Applications will need knowledge of the database and how to access it, unnecessary plumbing code is needed to manage the pool, data access objects will no longer be coded to EE specs making them less portable, no built-in or plug-in transaction management resulting in more plumbing code, an ever-growing number of connections as more applications are developed, performance degradation during high-traffic periods as connections become scarce, support overhead from managing many individual configurations, and the list goes on. It's possible each of these problems can be solved but as you solve them your code moves further and further from the EE specs. Because of all these problems, this is not an attractive solution.
The second solution is to move the responsibility for database authentication from Tomcat to the application. Recall the auth attribute of the
The third solution is to take advantage of Tomcat's built-in extensibility. Inside the
The source code for BasicDataSourceFactory has two important methods. They are:
public Object
getObjectInstance(
Object o
, Name n
, Context c
, Hashtable h)
public static DataSource
createDataSource(
Properties p
)
Tomcat creates an instance of BasicDataSourceFactory by calling its no-argument constructor. When a DataSource is needed the getObjectInstance(...) method is called. The BasicDataSourceFactory class implements this method in the following way. First it typecasts the Object parameter to Reference. Then all of the name/value pairs are removed from the Reference object and set in a Properties object. Finally, the Properties object is passed to the createDataSource(...) method where it's assumed the username and password exist in the Properties object as clear text.
To secure Tomcat database usernames and passwords, create a new class named EncryptedDataSourceFactory that extends BasicDataSourceFactory. This new class is going to override the getObjectInstance(...) method. The new method is implemented in the following way. First it will remove the encrypted username and passwords from the Reference object. Next, it will decrypt them. Then it will put the decrypted values into the Reference object. Finally it will call the getObjectInstance(...) method of the super class so it can take care of creating the DataSource. See the source code in Listing 3.
In the source code the "username" string of the setUsername() method and the "password" string of the setPassword() method refer to the
CIO, CTO & Developer Resources
These strings have corresponding constants in the BasicDataSourceFactory class but the constants are declared private so can't be used. The find() method throws an exception if not found because decryption will fail if there's nothing to decrypt. The decrypt() method uses a Base64 decoder that isn't secure but adequately demonstrates the concept. Finally the replace() method removes the encrypted values and puts in the decrypted values. When getObjectInstance(...) of the super class is called, it has the clear text passwords and is completely unaware that the values in server.xml are actually encrypted.
Using EncryptedDataSourceFactory is simple. First drop the org.moss.jdj.jdbc-yyyy.mm.dd.x.jar file into TOMCAT/server/lib. Next, get a Base64 encoding of the username and password. A simple Yahoo! search of "online base64 encoder" will find sites that will do it. Finally, edit server.xml and replace the username and password values with their corresponding Base64 equivalents and set the factory value to org.moss.jdj.dbcp.EncryptedDataSourceFactory. Start up Tomcat and see it in action.
Using Tomcat's built-in extensibility like this is an attractive solution. It fulfills security audit requirements by removing clear text usernames and passwords but it also lets applications be coded to EE specs. Using this solution doesn't put any unnecessary or unwanted responsibility in applications. Applications can be developed to fulfill business requirements and don't have to worry about plumbing code like initializing or shutting down a database connection pool properly, maintaining a custom transaction system to roll back on errors, or implementing an encryption strategy. Plus, when the time comes to move away from Tomcat the applications will be ready. The code in Listing 3 will be thrown away but small amounts of throwaway code is much better than the effort needed to go back and update applications.
Reading "To ESB or not to ESB"
To ESB or not to ESB
July 6th, 2009

Many of us have had to ponder this question. Technology selection is notoriously difficult in the enterprise space since the criteria and complexity of the problem is often not fully understood until later in the development process.
There is an interesting post from ThoughtWorker Erik Dörnenburg with the unfortunate title “Making the ESB pain Visible”. Erik provides a real-world example of when not to use an ESB citing that -
Based on conversations with the project sponsors I began to suspect that at least the introduction of the ESB was a case of RDD, ie. Resume-Driven Development, development in which key choices are made with only one question in mind: how good does it look on my CV? Talking to the developers I learned that the ESB had introduced “nothing but pain.” But how could something as simple as the architecture in the above diagram cause such pain to the developers? Was this really another case of architect’s dream, developer’s nightmare?
Later, Erik quite rightly points out that an ESB should not have been used in this scenario. This is a fairly common problem for ESBs and other enterprise technology like BPM/BPEL where the technology is not chosen for the right reasons and then the technology gets blamed when the project struggles. Given that much of the enterprise software disillusionment today stems from the incorrect usage of the technology I thought I’d offer some rough guidelines for selecting an ESB.
ESB selection checklist
Mule and other ESBs offer real value in scenarios where there are at least a few integration points or at least 3 applications to integrate. They are also well suited to scenarios where loose coupling, scalability and robustness are required.
Here is a quick ESB selection checklist –
- Are you integrating 3 or more applications/services? If you only need to communicate between 2 applications, using point-to-point integration is going to be easier.
- Will you really need to plug in more applications in the future? Try and avoid YNNI in your architecture. It’s better to keep things simple re-architect later if needed.
- Do you need to use more than one type of communication protocol? If you are just using HTTP/Web Services or just JMS, you’re not going to get any of the benefits if cross protocol messaging and transformation that Mule provides.
- Do you need message routing capabilities such as forking and aggregating message flows, or content-based routing? Many applications do not need these capabilities.
- Do you need to publish services for consumption by other applications? This is a good fit for Mule as it provides a robust and scalable service container, but in Erik’s use case all they needed was an HTTP client from their front-end Struts application.
- Do you have more than 10 applications to integrate? Avoid big-bang projects and consider breaking the project down in to smaller parts. Pilot your architecture on just 3 or 4 systems first and iron out any wrinkles before impacting other systems.
- Do you really need the scalability of an ESB? It’s very easy to over-architect scalability requirements of an application. Mule scales down as well as up making it a popular choice for ‘building in’ scalability. However, there is a price to be paid for this since you are adding a new technology to the architecture.
- Do you understand exactly what you want to achieve with your architecture? Vendors often draw an ESB as a box in the middle with lots of applications hanging off it. In reality, it does not work like that. There is a lot details that need to be understood first around the integration points, protocols, data formats, IT infrastructure, security etc. Starting small helps to keep the scope of the problem manageable and keep the fuckupery to a minimum. Until you understand your architecture and scope it properly you can’t really make a decision as to whether an ESB is right for you.
- Generally, always validate a product solution for your needs. Don’t choose an ESB or any other technology because –
- It will look good on my resume
- I don’t need the features today but there is a remote chance that I _might_ in future
- I had a great golfing weekend with the head of sales
This checklist is not exhaustive, but will help clarify when not to use an ESB. Once you have decided that an ESB is a good fit for your project you’ll want to add additional selection criteria such as connectivity options, robustness, error management, service repository, performance, data support, etc. The important thing to remember is that there is no silver bullet for good architecture and you need to know your architecture before making a technology decision.
With this checklist in mind it’s easy to see that Erik’s example never needed an ESB in the first place.
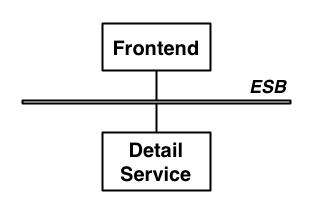
However, if the architecture looked something more like this, then an ESB would have probably been a good fit.

Choosing Mule
Obviously, as the creator of Mule I have some bias for wanting everyone to use Mule. However, it is critical to the continued success of the Mule project and to MuleSource that users understand when not to use an ESB. Open source makes a lot of sense for enterprise software because projects need time to try out the technology and refine their proposed architecture. Having access to the product and source code helps a huge amount in this discovery process and allows the customer to make an informed decision.
In fact the MuleSource business model hinges on the ability of the user to self-select Mule and approach us only when they need development or production support. This has been working very well for everyone involved. Customers get to do a proof of concept (PoC) with our product knowing that if they end up using it for a mission critical application that they can get professional 24×7 support. For MuleSource it means that our customers buy from us rather than us selling to them, so they always get what they want – this is a far cry from the old proprietary upfront license model that used to hold the enterprise market hostage.
Subscribe to:
Posts (Atom)