Monday, December 7, 2009
Difference between labor and professional
Wednesday, November 18, 2009
A guide to Java SimpleDateFormat in examples
Today I want to show you some examples of how you can use SimpleDateFormat class in your code. I hope some of them will be new and surprising!
The basic example
First the most basic usage of the class. Lets use it to format Date object into a simple string showing day, month and a year:
1: | SimpleDateFormat simpleDateFormat = |
Slightly more advanced
Obviously we can use more complicated patterns than that (see SimpleDateFormat JavaDoc for the full list). Besides adding more data to be shown we can also add some regular text – to do that in a pattern you need to escape the text with an apostrophe. So here is a fancy way of printing the time and date:
1: | SimpleDateFormat simpleDateFormat = |
Now with Locale
SimpleDateFormat is Locale dependent, so by providing one you can get the Date string localized for specific language or country. This is a date in French:
1: | SimpleDateFormat simpleDateFormat = |
Parse String to Date
Good thing about the SimpleDateFormat class is that it can be used not only for formatting, but also for parsing string into a Date object. In this example the used pattern is exactly the same as used by Date.toString() method. With it we can parse the strings created by Data.toString() back into dates:
1: | // SimpleDateFormat that works exactly like Date.toString() |
Setting the default time zone
Notice that when you parse a string into a Date the result may be ambiguous. For example the string “11:23 1 Jan 2001″ is a different moment in time depending whether you live in Japan or Canada. By default Java resolves this by using your local time zone obtained from the default Locale.
Since the time zone may not be a part of the parsed string you may want to set it manually instead using the default one. You can do this with setTimeZone() method:
1: | SimpleDateFormat simpleDateFormat = |
Setting the century
Similar ambiguity occurs when parsing two-digit year dates. Whether “01/01/59″ is the new year’s day of 1959 or 2059 can be set by specifying the century to the SimpleDateFormat object. To be specific with set2DigitYearStart() method you can specify the 100 year period in which the parsed date will be placed. By default the 100 year period is [today - 80 years, today + 20 years]. See the example:
1: | SimpleDateFormat simpleDateFormat = |
Make the parsing more strict
By default the parse method of SimpleDateFormat is very forgiving. If the provided string is not entirely compatible with the pattern, SimpleDateFormat instead of giving up tries with many tricky heuristics to guess what would be the correct answer. In many situations this behavior is more than welcome, but if you do not like this you can disable it. With setLenient() method you can make the parsing obey exactly the pattern and throw an exception if string is invalid.
1: | SimpleDateFormat simpleDateFormat = |
10 Java Regular Expression Examples You Should Know
Wednesday, October 21, 2009
Manager manage the system, not the people
Manager should create a system which:
1. People can do their job efficient.
2. People can get and give feedback.
3. People can grow.
Wednesday, October 14, 2009
Wednesday, October 7, 2009
Agile vs Lean
-Add Nothing But Value (Eliminate Waste)
-Center On The People Who Add Value
-Flow Value From Demand
-Optimize Across Organizations
The Agile Manifesto says:
-Individuals and interactions over processes and tools
-Working software over comprehensive documentation
-Customer collaboration over contract negotiation
-Responding to change over following a plan
waterfall vs rup vs scrum vs lean

Recently I got a very interesting blog regarding difference between above project methods.
Here’s a VERY simple overview of the main differences between Waterfall Development, Iterative Waterfall Development, Scrum/Agile Development and Lean.
Waterfall Development
‘Waterfall Development’ is another name for the more traditional approach to software development.
It’s called ‘waterfall’ as this type of development is often planned using a Gantt chart – you complete one phase (e.g. planning) before moving on to the next phase (e.g. development).
In Waterfall approaches, you will rarely aim to re-visit a ‘phase’ once it’s completed. As such, you better get whatever you’re doing right the first time!
This approach is highly risky, often more costly and generally less efficient than more Agile approaches.
The main issues with this approach include:
- You don’t realise any value until the end of the project (when you deploy) (See: Self-Funding Projects, a Benefit of Agile Software Development)
- You leave the testing until the end, which means you’re leaving issue discovery until late in the day
- You don’t seek approval from the stakeholders until late in the day – their requirements might have changed
- You’re heavily reliant upon a plan, which you can/will often follow to the detriment of the end result
- You’re heavily reliant upon a project manager driving the way – the power of one
Iterative Waterfall Development
This approach carries less risk than a traditional Waterfall approach but is still far more risky and less efficient than a more Agile approaches.
The focus is on delivering a sprint of work as opposed to a series of valuable/shippable features.
The most commonly occurring issue in this type of scenario (in my experience) is bottle necking.
For example, you deliver loads of code a little bit behind schedule (?) and you leave it until the last minute to test everything. One issue takes longer than expected to resolve, you miss your sprint deadline and you deliver nothing.
Another common symptom of this type of approach is over-commitment. It’s really difficult to estimate the total effort associated with a particular User Story/Feature when approaching delivery in this phased way.
You’re more or less forced to estimate each phase separately (e.g. estimate development separately to testing in this instance) – this doesn’t work as the phases are not separate, they’re totally intertwined.
For example, if you find an issue with the test, you must return to development. The whole team must remain focused on delivering the end goal, not the separate phases.
It’s also worth noting that velocity and burn downs are far less (if at all) useful in this type of environment – you don’t benefit from early-warning-signs as you don’t find out whether you’re on track until the end of the sprint.
Scrum Development
This approach carries far less risk than Waterfall approaches.
We focus on delivering fully-tested, independent, valuable, small features. As such, we diversify our risk – if one feature goes wrong, it should not impact another feature.
With that said, we still plan our work in iterations and we will still release at the end of each iteration.
Lean Development
Lean is very similar to Scrum in the sense that we focus on features as opposed to groups of features – however Lean takes this one step further again.
In Lean Development, you select, plan develop, test and deploy one feature (in its simplest form) before you select, plan, develop, test and deploy the next feature. By doing this, you further isolate risk to a feature-level.
In these environments, you aim to eliminate ‘waste’ wherever possible – you therefore do nothing until you know it’s necessary or relevant.
Tuesday, October 6, 2009
Why software is expensive
- Software is expensive because there are huge overhead costs associated with software development. Computer equipments are expensive. And the fact that software developers need to stay on the cutting edge of the technology means that they need to always upgrade their hardware. Also, software methodologies and tools change very often, software developers need to invest a lot of time and money to just to keep up with the development so that they can provide better service to their clients next time.
For those of you who think that hardware cost is "just of small fraction of the total cost", let me tell you that hardware is not cheap in third world countries; a mere acer laptop is costing as much as a programmer's one month salary here in Malaysia. - Software is expensive because there are a lot of research going into it. Some express puzzle at software developer apparent "low productivity" (20 lines of code per day). Assuming that you are charging USD 50 per hour, your rate is USD 20/line. This is awfully expensive to the business owners who measure productivity in terms of quantity produced. What they miss out is that programming productivity is all about writing less code to get your job done. A programmer could spend one billable month reinventing the wheel and produce a 10 million line-of-code ORM that is buggy, or spend one non-billable month to look for an open source implementation that is mature and well-developed, and endure the complain of low productivity. The way business owners complain about "research time" is encouraging the wrong type of behavior.
- Software is expensive because the product owners don't know what they want. Imagine if you go to an architect, asking him to provide a blue print, and after he comes out with that you ask him to change it according to your latest taste-- even though it is contrary to the original specification, and you repeat this process,.. No one would dare to do this, but everyone seems to have no problem asking the software developers to change their code at last minute and expect everything to work just fine and the product ships in time and worse of all, is not willing to pay extra.
- Software is expensive because it is customized only for you. The reason why Microsoft Office and Windows Vista is so cheap, is because the development cost is spread over million of users. The consequence of this is that there is no competitive advantage associated with the ordinary office or Windows Vista users. Your customized application, on the other hand, is designed especially for you, and you-- and no one else-- can enjoy the returns and benefits bring forth by the application.
Tuesday, September 29, 2009
URI, URL, URN
Have you ever carefully noticed the string in the address bar of your browser? What is it? Is it a URI or URL or URN? Some of us can’t differentiate between URI and URL and URN. Some non technical persons even don’t know the terms URI and URN. They just call that string a URL. Let’s understand this concept in deep.
Full Forms:
URI - Uniform Resource Indicator
URL - Uniform Resource Locator
URN - Unifrorm Resource Name
Definition:
URI: A URI indicates the name and the address of the resource on the web. The URI is further subdivided into URL and URI. It means URL and URI are the components of URI. definition
URL: A URL is the address of some resource on the web. A URL defines how the resource can be obtained and from where it can be obtained.
URN: A URN is the name of some resource on the web. A URN does not imply the availability of the identified resource and never tells about how the resource can be obtained.
So, one can say URI = URL + URN
Example:
If i say “My name is Roy”, then it will be a URN, just telling the name of a person not the proper location.
If i say “I live in New York”, then it will be a URL, telling me the location of a person.
If i say “My name is Roy and I live in New York”, then its proprer URI.
Ambiguity: Its the matter of ambiguity whether the term URL is deprecated or not. Some argue yes and some no. Some say that the more correct term is URI, used in technical documentation. All URIs are means to access a resource on the Internet and are a technical short hand used to link to the resource. URIs always designate a method to access the resource and designate the specific resource to be accessed. So should we use the term URI instead of most popular term URL?
Conclusion:
URI is an abstract concept while URL and URN are the concrete implementations of a URI and one should always know the difference among all the three.
Monday, September 28, 2009
What is difference between n-tiered and n-layered
Layered is logical separation, for example presentation layer, business layer, DAO layer.
Thursday, September 17, 2009
OOP principal
| SRP | The Single Responsibility Principle | A class should have one, and only one, reason to change. |
| OCP | The Open Closed Principle | You should be able to extend a classes behavior, without modifying it. |
| LSP | The Liskov Substitution Principle | Derived classes must be substitutable for their base classes. |
| DIP | The Dependency Inversion Principle | Depend on abstractions, not on concretions. |
| ISP | The Interface Segregation Principle | Make fine grained interfaces that are client specific. |
The next six principles are about packages. In this context a package is a binary deliverable like a .jar file, or a dll as opposed to a namespace like a java package or a C++ namespace.
The first three package principles are about package cohesion, they tell us what to put inside packages:
| REP | The Release Reuse Equivalency Principle | The granule of reuse is the granule of release. |
| CCP | The Common Closure Principle | Classes that change together are packaged together. |
| CRP | The Common Reuse Principle | Classes that are used together are packaged together. |
The last three principles are about the couplings between packages, and talk about metrics that evaluate the package structure of a system.
| ADP | The Acyclic Dependencies Principle | The dependency graph of packages must have no cycles. |
| SDP | The Stable Dependencies Principle | Depend in the direction of stability. |
| SAP | The Stable Abstractions Principle | Abstractness increases with stability. |
Wednesday, September 9, 2009
What is architecture
In most successful software project, the expert developer working on the project have a shared understanding of the system design. The shared system design is called "Architecture". The shared understanding includes how the system is divided into components and how those components interacts through interfaces. Those components are usually composed of small components, but the architecture only includes those components and interfaces that understandable by all developers. Architecture is about important stuff, whatever is.
Booch said:
All architecture are design, but not all design is architecture. Architecture represents the significant design decision that shapes a system where significant is measured by the cost of change.
The goal of architecture is eliminate the impact and cost of change.
Making everything easy to change makes the entire system complex.
Monday, August 24, 2009
Insteresting reading points
B. If the only tool you have is a hammer, then everything looks like a nail.
C. Nothing is permanent than temporary patch in a system.
Tuesday, August 18, 2009
Monday, August 17, 2009
powerbuilder path
T:\jonview_soket\jonview_socket.pbl;
T:\jonview_soket\proxy_socket_call.pbl;
jonview_remote
T:\jonview_remote\jonview_remote.pbl;
T:\jonview_remote\remote_call.pbl;
T:\jonview_remote\remote_fun.pbl;
T:\jonview_remote\remote_call_new.pbl;
T:\jonview_remote\remote_fun_new.pbl;
jonviewhostclient
T:\jonviewclient\client\jonviewclient\jonviewhostclient.pbl;
T:\jonviewclient\client\jonviewclient\voucher.pbl;
T:\jonviewclient\client\jonviewclient\jonview_report.pbl;
T:\jonviewclient\client\jonviewclient\jonview_report_win.pbl;
T:\jonviewclient\client\jonviewclient\jonview_report2.pbl;
T:\jonviewclient\client\jonviewclient\jonviewclient_proxy.pbl;
T:\jonviewclient\client\jonviewclient\library.pbl;
T:\jonviewclient\client\jonviewclient\jonview_common.pbl;
jonviewhostserver_trion
T:\jonviewhost_xml\jonviewhostserver_allian.pbl;
T:\jonviewhost_xml\xml_exchange.pbl;
T:\jonviewhost_xml\jonviewproxy.pbl;
T:\jonviewhost_xml\jonview_common.pbl;
T:\jonviewhost_xml\jonview_xml_parent.pbl;
T:\jonview_web\common\jonview_public_common.pbl;
T:\jonview_web\common\jonview_public_product.pbl;
T:\jonview_web\common\jonview_public_trion.pbl;
T:\jonview_web\common\jonview_public_h2h.pbl;
T:\jonview_web\common\jonview_public_string.pbl;
T:\jonview_web\common\jonview_public_login.pbl;
T:\jonview_web\common\jonview_public_tariff.pbl;
T:\jonviewhost_xml\jonview_xml_download.pbl;
jonviewhostserver_xml
T:\jonviewhost_xml\jonviewhostserver.pbl;
T:\jonviewhost_xml\jonview_xml_parent.pbl;
T:\jonviewhost_xml\xml_exchange.pbl;
T:\jonviewhost_xml\jonviewproxy.pbl;
T:\jonviewhost_xml\jonview_allian_proxy.pbl;
T:\jonviewhost_xml\jonview_common.pbl;
T:\jonview_web\common\jonview_public_common.pbl;
T:\jonview_web\common\jonview_public_product.pbl;
T:\jonview_web\common\jonview_public_trion.pbl;
T:\jonview_web\common\jonview_public_h2h.pbl;
T:\jonview_web\common\jonview_public_string.pbl;
T:\jonview_web\common\jonview_public_login.pbl;
T:\jonview_web\common\jonview_public_tariff.pbl;
T:\jonviewhost_xml\jonview_xml_download.pbl;
jonviewhostserver
T:\jonviewhost_all\jonviewhostserver.pbl;
T:\jonviewhost_all\jonview_core_proxy.pbl;
T:\jonviewhost_all\jonview_common.pbl;
T:\jonview_web\common\jonview_public_paxspecial.pbl;
T:\jonview_web\common\jonview_public_nvo.pbl;
jonviewhostserver_voucher
T:\jonviewclient\jonviewhostserver_voucher.pbl;
T:\jonviewclient\jonviewhostserver_father.pbl;
T:\jonviewclient\jonview_common_fun.pbl;
T:\jonviewclient\voucher.pbl;
T:\jonview_web\common\jonview_public_common.pbl;
T:\jonview_web\common\jonview_public_product.pbl;
T:\jonview_web\common\jonview_public_string.pbl;
jonviewhostserver_report
T:\jonviewclient\jonviewhostserver_report.pbl;
T:\jonviewclient\jonviewhostserver_father.pbl;
T:\jonviewclient\jonview_common.pbl;
T:\jonviewclient\jonview_common_fun.pbl;
T:\jonviewclient\jonview_report2.pbl;
T:\jonviewclient\jonview_report.pbl;
jonviewhostserver(jonviewclient)
T:\jonviewclient\jonviewhostserver.pbl;
T:\jonviewclient\jonviewhostserver_father.pbl;
T:\jonviewclient\jonview_core_proxy.pbl;
T:\jonviewclient\jonview_common.pbl;
T:\jonviewclient\jonview_common_fun.pbl;
T:\jonviewclient\jonviewhost_xmlproxy.pbl;
T:\jonviewclient\jonviewhost_pdfproxy.pbl;
T:\jonview_web\common\jonview_public_common.pbl;
T:\jonview_web\common\jonview_public_product.pbl;
T:\jonview_web\common\jonview_public_string.pbl;
jonview_trion
T:\jonview_trion\jonview_trion.pbl;
T:\jonview_trion\jonview_trion_common.pbl;
T:\jonview_trion\jonview_proxy.pbl;
T:\jonview_web\common\jonview_public_string.pbl;
T:\jonview_web\common\jonview_public_common.pbl;
T:\jonview_web\common\jonview_public_reference.pbl;
T:\jonview_web\common\jonview_public_product.pbl;
T:\jonview_web\common\jonview_public_trion.pbl;
T:\jonview_web\common\jonview_public_h2h.pbl;
T:\jonview_web\common\jonview_public_login.pbl;
T:\jonview_web\common\jonview_public_paxspecial.pbl;
T:\jonview_web\common\jonview_public_report.pbl;
T:\jonview_web\common\jonview_public_itinerary.pbl;
T:\jonview_web\common\jonview_public_transportation.pbl;
T:\jonview_web\common\jonview_public_nvo.pbl;
T:\jonview_web\common\jonview_public_tariff.pbl;
jonview_pdf
T:\jonview_pdf\jonview_pdf.pbl;
T:\jonview_pdf\proxy_mail.pbl;
jonview_public
T:\jonview_web\public\jonview_public.pbl;
T:\jonview_web\public\jonview_public_alternate.pbl;
T:\jonview_web\common\jonview_public_common.pbl;
T:\jonview_web\common\jonview_public_login.pbl;
T:\jonview_web\common\jonview_public_tariff.pbl;
how to fix activeMq inactive errors.
from
transportConnector name="openwire" uri="tcp://localhost:61616" discoveryUri="multicast://default"
to
transportConnector name="openwire" uri="tcp://localhost:61616?wireFormat.maxInactivityDuration=0"
Thursday, August 13, 2009
Inversion of control and dependency injection
1. decoupling execution and its implementation
2. Every system focus on what it is designed for.
3. Every system does not what other system will do or should do.
4. Changing one system will not affect others.
Techniques:
1. Factory pattern.
2. setter injection
3. Constructor injection.
4. Services Locater
5. Interface injection
Dependency Injection is decoupling high level modules from low level services.
Monday, August 10, 2009
template VS stragety
Strategy is used to allow callers to vary an entire algorithm, like how to calculate different types of tax, while Template Method is used to vary steps in an algorithm. Because of this, Strategy is more coarsely grained. The Template allows finer-grained controls in the sequent of operations, and yet allows the implementations of these details to vary.
The other main difference is that Strategy uses delegation while Template Method uses inheritance. In Strategy, the algorithm is delegated to the another xxxStrategy class that the subject will have a reference to, but with Template you subclass the base and override methods to make changes.
Strategy pattern example:
Class MainSubject
{
}ITaxStrategy taxCalculator = GetStrategy(taxType);
//strategy is member class.
taxCalculator.Calculate();
private GetStrategy(string taxType)
{if (taxType == "incometax")
return new IncomeTaxStrategy();
else if (taxType == "propertytax")
return new PropertyTaxStrategy();
}
Class IncomeTaxStrategy : ITaxStrategy
{
public Calculate()
{
//calculate based on income tax rates.
}
}
Class PropertyTaxStrategy : ITaxStrategy
{
public Calculate()
{
//calculate based on property tax
policies.
}
}
Template pattern example:
abstract Class TaxCalculator
{
public CalculateTax()
{CalculateIncome();
tax =+ CalculateTax();
tax =+ CalculateRelief();
}
abstract CalculateTax();
abstract CalculateRelief();
}
Class IncomeTaxCalculator : TaxCalculator
{
override CalculateTax() { //calculate income tax. }
override CalculateRelief() { //calculate personal relief }
}
Class PropertyTaxCalculator : TaxCalculator
{
override CalculateTax() { //calculate property tax. }
override CalculateRelief() { //do nothing; no relief. }
}
Wednesday, July 29, 2009
String.substring is dangerous
String sub = new String( oldString.substring(0, 4) );
Tuesday, July 28, 2009
Good Developer
limited to past experience.
Monday, July 27, 2009
What is the difference between class adapter and object adapter design pattern
If you have multiple adaptees, then you have to use object adapter.
// Object adapter version
public class ReportGenerator implements OldReporter {
private NewReportWriter newReporter = new NewReportWriter()
public void writeHeader(String headerData) {
newReporter.generateHeaderLines(headerData)
}
}
// Class adapter version
public class ReportGenerator extends NewReportWriter
implements OldReporter {
public void writeHeader(String headerData) {
generateHeaderLines(headerData)
}
}
Friday, July 24, 2009
design pattern Singleton
- public class SimpleSingleton {
- private SimpleSingleton singleInstance = null;
- //Marking default constructor private
- //to avoid direct instantiation.
- private SimpleSingleton() {
- }
- //Get instance for class SimpleSingleton
- public static SimpleSingleton getInstance() {
- if(null == singleInstance) {
- singleInstance = new SimpleSingleton();
- }
- return singleInstance;
- }
- }
public static synchronized SimpleSingleton getInstance() { }
Thursday, July 23, 2009
How to do as architect
a. help the stakeholders to list all non-functional requirement:
performance, security, scalability, availability, maintainability, audit, extensibility and I18N
2. Architecture definition
Every system has a architecture, but not every has a architecture defined. The architecture definition process lets you think about how you're going to take the requirements plus any constraints imposed upon you and figure out how you're going to solve the problem. Architecture definition is about introducing structure, guidelines, principles and leadership to the technical aspects of a software project.
3. Technology selection
4. Architecture evaluation
Risk, benefit.
5. Architecture collaboration
Go through it and make sure everybody involved understand it and buy in.
6. Ownership of big picture.
7. leadership
Taking responsibility, providing technical guidance, making technical decisions and having the authority to make those decisions
8. Coaching and mentoring
Sharing experience with other members.
9. Design, development and testing
10. Quality assurance
Tuesday, July 21, 2009
String, Stringbuilder, and stringbuffer
For concat(), string builder is better, but JVM automatically does it for you.
Stringbuilder is not thread-safe
Stringbuffer is thread-safe.
TDD steps
2. Write the comments inside the test to describe the function
3. Write sub-test for each function inside the test.
4. Run the test, make the testing running automatically.
5. Write the code.
6. re-factory the test.
Monday, July 20, 2009
reading comments: Lazy Load
lazy initialization
With lazy initialization, every access to the field is checked against a special value, e.g. null value. If the value is not found, then the object needs to perform some logic, e.g. lookup from database, before returning.
virtual proxy
A virtual proxy is an object that looks like the object that should be in the field, but actually doesn’t contain anything. Only when one of it’s methods is called does it load the correct object from the database.
value holder
A value holder is used as a generic Lazy Load. It is an object that wraps some other object. To get the underlying object you ask the value holder for the value, and the first access will pull the data from the database.
XmlBeanFactory vs ClassPathXmlApplicationContext
When we use XmlBeanFactory, TX annotation is not working. and it does not even load when you say
So if you want to use annotation, please use ClassPathXmlApplicationContext. I believe in WEB application, tomcat system actually uses ClassPathXmlApplicationContext. So in order to make your code testing separately, please do not use XmlBeanFactory.
Below it is the example of XmlBeanFactory and ClassPathXmlApplicationContext
XmlBeanFactory factory = new XmlBeanFactory(new ClassPathResource(
"applicationContext2.xml"));
InvoiceProcessDao process = (InvoiceProcessDao)factory.getBean("invoiceProcess");
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext3.xml");
InvoiceProcessDao process = (InvoiceProcessDao)ctx.getBean("invoiceProcess");
process.checkPayment();
System.out.println(" Over") ;
Monday, July 13, 2009
Junit best pratise
JUnits - Do’s and Dont’s
A JUnit test case can contain multiple tests. Each test is implemented by a method. The declaration of a test method must comply to a set of conventions in order to help JUnit and associated tools to automate the discovery and execution of tests. These conventions are:
1. The name of the method must begin with “test”, like in “testValidateOperator”,
2. The return type of a test method must be null,
3. A test method must not throw any exception,
4. A test method must not have any parameter.
There are a few details of which you should be aware of when writing JUnit tests. First of all, when executing a test case, JUnit will instantiate the test case class as many time as there are test methods. That is, each test method will be executed on a different instance of the test case class. Before calling the test method, JUnit will call the setUp() method. The tearDown() method will be called after the test method completes – successfully or not. The setUp() and tearDown() methods should be used to create and then clean up the test environment.
Good practices to be followed while writing a JUnit:
• Write tests for methods that have the fewest dependencies first. If you start by testing a high-level method, your test may fail because a subordinate method may return an incorrect value to the method under test. This increases the time spent finding the source of the problem, and you will still have to test the subordinate method anyway to be sure it does not contain other bugs.
• Tests should be logically simple as possible, preferably with no decisions at all. Every decision added to a test method increases the number of possible ways that a test method can be executed. Testing is meant to be a controlled environment; the only thing you want to change is the input to the method under test, not the test method itself.
• Wherever possible, use constant as expected values in your assertions instead of computed values. Consider these two assertions:
returnVal = getDiscountCode(input);
assertEquals(returnVal, computeDiscountCode(input));
assertEquals(returnVal, “023”);
In order for computeDiscountCode() to return the proper result it probably has to implement the same logic as the getDiscountCode(), which is what you are trying to test for in the first place. Further, suppose you fixed a defect in the getDiscountCode (). Now you have to change computeDiscountCode () in the same manner. The second assertion is easier to understand and maintain.
• Each unit test should be independent of all other tests.
A unit test should execute one specific behavior for a single method. Validating behavior of multiple methods is problematic as such coupling can increase refactoring time and effort. Consider the following example:
void testAdd()
{
int return1 = myClass.add(1,2);
int return2 = myclass.add(-1,-2);
assertTrue (return1 – return2 == 0);
}
If the assertions fails in this case, it will be difficult to determine which invocation of add() caused the problem.
• Each unit test should be clearly named and documented.
The name of the test method should clearly indicate which method is being tested because improperly named tests increase maintenance and refactoring efforts. Comments should also be used to describe the test or any special conditions.
• All methods, regardless of visibility, should have appropriate unit tests.
Public, private and protected methods that contain data and decisions should be unit tested in isolation.
• One assertion per test case.
Avoid using multiple assertions in one test case. For example, if a test case with five assertions fails on the first assertion, then the remaining four are not executed. Only when the first assertion is corrected will the other assertions execute. If assertion two fails, then that also must be corrected before the remaining three assertions are verified. Although the unit test file may be large, it will be easier to find and fix defects.
• Create unit tests that target exceptions.
Exceptions are thrown when a method finds itself in a state it cannot handle. These cases should be tested just like a method’s normal state of operations. If a method is declared to throw one or more exceptions, then unit tests must be create that simulate the circumstances under which those exceptions could be thrown. The unit tests should assert that the exceptions are thrown as expected.
Please let me know if this helps. Happy coding Junits…!!
Wednesday, July 8, 2009
SOA Security post
http://cwiki.apache.org/CXF20DOC/ws-security.html
Tuesday, July 7, 2009
Notes for Data Warehousing
a. Operational Data ( OLTP)
- Data that works
- Frequent updated and queried
- Normalized for efficient search and update
- Fragmented and local relevance.
- Point query, query access individual tables.
What is the salary of John?
What is the phone number of the person who is in charge of Depta
How many people are rated as excellent?
b. Historical Data (OLAP)
- Data that tells
- Very infrequent update
- Integrated data set with global relevance.
- Analytical queries that require huge amounts of aggregation.
- performance issue, need quick response time.
How is the trend in the past 2 years?
How is summary of something?
2. What is Data Warehousing?
- An infrastructure of manage historical data
- Designed to support OLAP queries involving gratuitous use of aggregation
- Post retrival processing(reporting)
4. Data Marts:
- Segments of OLTP
- Data Warehouse is a collection of data marts
a. Dirt Data
- Lack of standardization
- Missing or duplicate data
- Inconsistent.
- Can not be fully automated
- GIGO
- Require data considerable knowledge
- Complex
- Data analysis
- Definition of transformation rule
- Rules verification
- Transformation
- Backflow: re-populate data
Schema: Forming an integrated schema structure from different data source, cleaning data and managing from different DS.
Reading: Tomcat security for clear password
How to Secure Tomcat Database Passwords for Java
In production environments there are features of Tomcat that don't pass security audit reviews
| October 3, 2007 11:45 AM EDT | Reads: | 30,463 |
Tomcat is a great reference implementation of the Java EE specification and is intended for desktop use by developers who are starting to learn about Java EE or those who work on enterprise applications and need an EE server for development. However because Tomcat is free it finds its way into production environments. In this environment there are features of Tomcat that don't pass security audit reviews. One of these features is the use of clear text passwords in the server.xml file to create data sources. The purpose of this article is to show how encryption of the username and password can be implemented thus closing a potential security vulnerability.
 Configuring a container managed data source with Tomcat is easy and well documented under the "JDBC DataSources" section of Tomcat's documentation (this article uses Tomcat 5.0.28). The data source configuration information is stored in TOMCAT/conf/server.xml. The resource is defined using the
Configuring a container managed data source with Tomcat is easy and well documented under the "JDBC DataSources" section of Tomcat's documentation (this article uses Tomcat 5.0.28). The data source configuration information is stored in TOMCAT/conf/server.xml. The resource is defined using the
auth="Container"
type="javax.sql.DataSource"
/>
The name attribute defines where the resource is bound in JNDI. The auth attribute will have either the value Application or Container. Container means Tomcat will provide the username and password to connect to the resource whereas Application means the application will provide them. Container is specified because the username and password will be entered in server.xml. The type attribute is the fully qualified name of the class returned when the resource is looked up using JNDI.
Next the resource needs to be configured. This is the purpose of the
The name attribute has the value jdbc/TestDB, which must match a
Finally, the application has to be configured to use this data source. This is done by referencing the data source in /META-INF/context.xml of the application's WAR. A
name="jdbc/SpiderMan"
type="javax.sql.DataSource"
/>
The type attribute is the fully qualified name of the class returned when the resource is looked up using JNDI. The global attribute must match a
For development environments or personal use this configuration is acceptable, however, in a production environment the clear text username and password in
While Yahooing! I was surprised to discover I couldn't find any instructions addressing this issue. Most search results related to debating if securing the clear text username and password is even necessary. The general consensus seemed to be this security is not necessary for two reasons. One, if an intruder compromises a production server in a way that would allow read access to server.xml then the clear text username and password is the least security concern. Two, Tomcat is a reference implementation so it shouldn't be used in a production environment. Although these are lively debates and can spark great topics of conversation they do not address the issue. What I need is a way to get rid of the clear text username and password.
I will present three possible solutions to this issue. The first two are custom solutions involving application updates while the third takes advantage of Tomcat's built-in extensibility, requires no application updates and so is a much more attractive solution.
The first solution is to bypass Tomcat altogether and not configure a data source. With no data source there's no clear text username and password in server.xml so the problem is solved. However applications still need database connections. With no container-managed database pool each application will have to do its own pooling. This brings up all sorts of problems. Applications will need knowledge of the database and how to access it, unnecessary plumbing code is needed to manage the pool, data access objects will no longer be coded to EE specs making them less portable, no built-in or plug-in transaction management resulting in more plumbing code, an ever-growing number of connections as more applications are developed, performance degradation during high-traffic periods as connections become scarce, support overhead from managing many individual configurations, and the list goes on. It's possible each of these problems can be solved but as you solve them your code moves further and further from the EE specs. Because of all these problems, this is not an attractive solution.
The second solution is to move the responsibility for database authentication from Tomcat to the application. Recall the auth attribute of the
The third solution is to take advantage of Tomcat's built-in extensibility. Inside the
The source code for BasicDataSourceFactory has two important methods. They are:
public Object
getObjectInstance(
Object o
, Name n
, Context c
, Hashtable h)
public static DataSource
createDataSource(
Properties p
)
Tomcat creates an instance of BasicDataSourceFactory by calling its no-argument constructor. When a DataSource is needed the getObjectInstance(...) method is called. The BasicDataSourceFactory class implements this method in the following way. First it typecasts the Object parameter to Reference. Then all of the name/value pairs are removed from the Reference object and set in a Properties object. Finally, the Properties object is passed to the createDataSource(...) method where it's assumed the username and password exist in the Properties object as clear text.
To secure Tomcat database usernames and passwords, create a new class named EncryptedDataSourceFactory that extends BasicDataSourceFactory. This new class is going to override the getObjectInstance(...) method. The new method is implemented in the following way. First it will remove the encrypted username and passwords from the Reference object. Next, it will decrypt them. Then it will put the decrypted values into the Reference object. Finally it will call the getObjectInstance(...) method of the super class so it can take care of creating the DataSource. See the source code in Listing 3.
In the source code the "username" string of the setUsername() method and the "password" string of the setPassword() method refer to the
These strings have corresponding constants in the BasicDataSourceFactory class but the constants are declared private so can't be used. The find() method throws an exception if not found because decryption will fail if there's nothing to decrypt. The decrypt() method uses a Base64 decoder that isn't secure but adequately demonstrates the concept. Finally the replace() method removes the encrypted values and puts in the decrypted values. When getObjectInstance(...) of the super class is called, it has the clear text passwords and is completely unaware that the values in server.xml are actually encrypted.
Using EncryptedDataSourceFactory is simple. First drop the org.moss.jdj.jdbc-yyyy.mm.dd.x.jar file into TOMCAT/server/lib. Next, get a Base64 encoding of the username and password. A simple Yahoo! search of "online base64 encoder" will find sites that will do it. Finally, edit server.xml and replace the username and password values with their corresponding Base64 equivalents and set the factory value to org.moss.jdj.dbcp.EncryptedDataSourceFactory. Start up Tomcat and see it in action.
Using Tomcat's built-in extensibility like this is an attractive solution. It fulfills security audit requirements by removing clear text usernames and passwords but it also lets applications be coded to EE specs. Using this solution doesn't put any unnecessary or unwanted responsibility in applications. Applications can be developed to fulfill business requirements and don't have to worry about plumbing code like initializing or shutting down a database connection pool properly, maintaining a custom transaction system to roll back on errors, or implementing an encryption strategy. Plus, when the time comes to move away from Tomcat the applications will be ready. The code in Listing 3 will be thrown away but small amounts of throwaway code is much better than the effort needed to go back and update applications.
Reading "To ESB or not to ESB"
To ESB or not to ESB
July 6th, 2009

Many of us have had to ponder this question. Technology selection is notoriously difficult in the enterprise space since the criteria and complexity of the problem is often not fully understood until later in the development process.
There is an interesting post from ThoughtWorker Erik Dörnenburg with the unfortunate title “Making the ESB pain Visible”. Erik provides a real-world example of when not to use an ESB citing that -
Based on conversations with the project sponsors I began to suspect that at least the introduction of the ESB was a case of RDD, ie. Resume-Driven Development, development in which key choices are made with only one question in mind: how good does it look on my CV? Talking to the developers I learned that the ESB had introduced “nothing but pain.” But how could something as simple as the architecture in the above diagram cause such pain to the developers? Was this really another case of architect’s dream, developer’s nightmare?
Later, Erik quite rightly points out that an ESB should not have been used in this scenario. This is a fairly common problem for ESBs and other enterprise technology like BPM/BPEL where the technology is not chosen for the right reasons and then the technology gets blamed when the project struggles. Given that much of the enterprise software disillusionment today stems from the incorrect usage of the technology I thought I’d offer some rough guidelines for selecting an ESB.
ESB selection checklist
Mule and other ESBs offer real value in scenarios where there are at least a few integration points or at least 3 applications to integrate. They are also well suited to scenarios where loose coupling, scalability and robustness are required.
Here is a quick ESB selection checklist –
- Are you integrating 3 or more applications/services? If you only need to communicate between 2 applications, using point-to-point integration is going to be easier.
- Will you really need to plug in more applications in the future? Try and avoid YNNI in your architecture. It’s better to keep things simple re-architect later if needed.
- Do you need to use more than one type of communication protocol? If you are just using HTTP/Web Services or just JMS, you’re not going to get any of the benefits if cross protocol messaging and transformation that Mule provides.
- Do you need message routing capabilities such as forking and aggregating message flows, or content-based routing? Many applications do not need these capabilities.
- Do you need to publish services for consumption by other applications? This is a good fit for Mule as it provides a robust and scalable service container, but in Erik’s use case all they needed was an HTTP client from their front-end Struts application.
- Do you have more than 10 applications to integrate? Avoid big-bang projects and consider breaking the project down in to smaller parts. Pilot your architecture on just 3 or 4 systems first and iron out any wrinkles before impacting other systems.
- Do you really need the scalability of an ESB? It’s very easy to over-architect scalability requirements of an application. Mule scales down as well as up making it a popular choice for ‘building in’ scalability. However, there is a price to be paid for this since you are adding a new technology to the architecture.
- Do you understand exactly what you want to achieve with your architecture? Vendors often draw an ESB as a box in the middle with lots of applications hanging off it. In reality, it does not work like that. There is a lot details that need to be understood first around the integration points, protocols, data formats, IT infrastructure, security etc. Starting small helps to keep the scope of the problem manageable and keep the fuckupery to a minimum. Until you understand your architecture and scope it properly you can’t really make a decision as to whether an ESB is right for you.
- Generally, always validate a product solution for your needs. Don’t choose an ESB or any other technology because –
- It will look good on my resume
- I don’t need the features today but there is a remote chance that I _might_ in future
- I had a great golfing weekend with the head of sales
This checklist is not exhaustive, but will help clarify when not to use an ESB. Once you have decided that an ESB is a good fit for your project you’ll want to add additional selection criteria such as connectivity options, robustness, error management, service repository, performance, data support, etc. The important thing to remember is that there is no silver bullet for good architecture and you need to know your architecture before making a technology decision.
With this checklist in mind it’s easy to see that Erik’s example never needed an ESB in the first place.
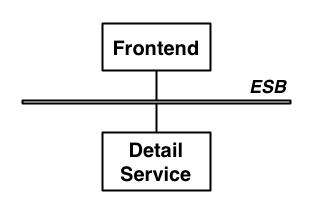
However, if the architecture looked something more like this, then an ESB would have probably been a good fit.

Choosing Mule
Obviously, as the creator of Mule I have some bias for wanting everyone to use Mule. However, it is critical to the continued success of the Mule project and to MuleSource that users understand when not to use an ESB. Open source makes a lot of sense for enterprise software because projects need time to try out the technology and refine their proposed architecture. Having access to the product and source code helps a huge amount in this discovery process and allows the customer to make an informed decision.
In fact the MuleSource business model hinges on the ability of the user to self-select Mule and approach us only when they need development or production support. This has been working very well for everyone involved. Customers get to do a proof of concept (PoC) with our product knowing that if they end up using it for a mission critical application that they can get professional 24×7 support. For MuleSource it means that our customers buy from us rather than us selling to them, so they always get what they want – this is a far cry from the old proprietary upfront license model that used to hold the enterprise market hostage.
Friday, June 26, 2009
JPA field access vs property access
Thursday, June 25, 2009
After reading "IT Managers confession"
- Good team knows how to handle their manager, train the manager to do things their way.
- As a manager, if you do not like someone and you can not get rid of him/her, then it is better promote him/her to another position, so he/she can leave the group. But keep the good people with you.
- Find a Yancey man who can speak for you. He has excellent communication skill , he can talk regular language to customers and stake holders. But you need him to follow you, speak your mind not his own mind. That is hard.
- Looking Busy:
- arrival early and leave late does not mean you hard, you can leave in the middle.
- Using MS project to create a lot of report.
- A lot of meeting and crisis management.
- Ask your developer to send everything for you to approval.
- visit other department regularly.
- find any chances to complain too many emails.
Tuesday, June 23, 2009
Spring JPA annotation transaction.
it's caused by the use of the BeanFactory instead of an ApplicationContext, which is used inside the unit test, behind the scene when using the AbstractJpaTests base class.
If you change your Main class to
public class Main {
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext("context/testContext.xml");
PersonDAO dao=(PersonDAO)ctx.getBean("personDAO");
Person p=new Person();
p.setFirstName("testName");
dao.save(p);
}
} The reason for that is a slightly different behavior between a BeanFactory and an ApplicationContext when it comes to BeanPostProcessors. From the Spring reference manual:
It is important to know that a BeanFactory treats bean post-processors slightly differently than an ApplicationContext. An ApplicationContext will automatically detect any beans which are defined in the configuration metadata which is supplied to it that implement the BeanPostProcessor interface, and register them as post-processors, to be then called appropriately by the container on bean creation. Nothing else needs to be done other than deploying the post-processor in a similar fashion to any other bean. On the other hand,
when using a BeanFactory implementation, bean post-processors explicitly have to be registered, with code
like this:
ConfigurableBeanFactory factory = new XmlBeanFactory(...);
// now register any needed BeanPostProcessor instances
MyBeanPostProcessor postProcessor = new MyBeanPostProcessor();
factory.addBeanPostProcessor(postProcessor);
// now start using the factory
This explicit registration step is not convenient, and this is one of the reasons why the various
ApplicationContext implementations are preferred above plain BeanFactory implementations in the vast majority of Spring-backed applications, especially when using BeanPostProcessors
That's the whole reason, why your PersistenceAnnotationBeanPostProcessor never got loaded and therefore couldn't do its work!
Tuesday, June 16, 2009
From dzone.com: Three Questions About Each Bug You Find
Three Questions About Each Bug You Find
I really love this timeless Tom Van Vleck article from 1989. It teaches us to ask ourselves:
Three Questions About Each Bug You Find
Those questions being:
- Is this mistake somewhere else also?
- What next bug is hidden behind this one?
- What should I do to prevent bugs like this?
When I first read these rules, I was foolish enough to think:
'Cute, But Too Obvious! i do this intuitively all the time.'
But watch yourself closely! I've caught myself out on occasion, and maybe you will too.
I'm making an effort to be more explicit about the three questions. Maybe i'll end up fixing related problem